Reinventing the Mortgage Data Core: Why Agentic AI Will Stall Without a Data Foundry
Mortgage banking is entering a decisive structural transition. Artificial intelligence—particularly agentic AI capable of autonomous decision-making—is no longer experimental. In 2026, it is becoming an operational expectation across underwriting, compliance, servicing, and secondary market execution.

Boards want scale. Regulators want explainability. Investors want consistency. Executives want margin relief in a structurally compressed market. However, across the industry, AI ambition is colliding with a persistent and largely unaddressed constraint: an ineffective mortgage data core.
This is not a question of insufficient tooling or cloud adoption. Mortgage institutions have invested heavily in loan origination systems, compliance engines, analytics platforms, AI copilots, and third-party fintech integrations. The limiting factor is architectural—not technological.
Even today, mortgage data remains fragmented across systems, inconsistently defined, weakly governed, and difficult to trace across the loan lifecycle. As a result, AI initiatives stall at scale, agentic workflows become brittle, and regulatory defensibility erodes precisely where automation is intended to reduce risk.
This article argues that the next era of mortgage competitiveness will not be determined by AI technological, engineering sophistication alone. It will be determined by whether institutions reinvent their data core through a data foundry model—an industrialized approach to creating reusable, explainable, and regulator-ready loan data products that can support agentic AI safely and at scale.
Mortgage Banking’s AI Ambition Meets Its Data Reality
By 2026, few mortgage executives question whether AI belongs in their operating model. The conversation has shifted from “if” to “how fast” and “how far.” AI is already embedded across the mortgage value chain:
• Underwriting assistants summarize borrower risk, income stability, and AUS findings.
• Pricing and product eligibility engines adapt dynamically to borrower, market, and investor conditions.
• Compliance tools scan disclosures, monitor fair lending indicators, and identify anomalies earlier in the process.
• Post-close and quality control teams use machine learning to prioritize high-risk loans.
• Servicing platforms apply predictive analytics to delinquency, forbearance, and loss mitigation.
At the same time, regulatory and counterparty scrutiny has intensified. Regulators expect clearer explanations of automated decisioning. Investors and warehouse lenders demand greater transparency into loan quality. Courts increasingly examine how data was used—not just what decision was made. Figure 1 highlights the demands being placed not just on AI, but the business models and the data underpinning operational and informational decisions within each data domain.
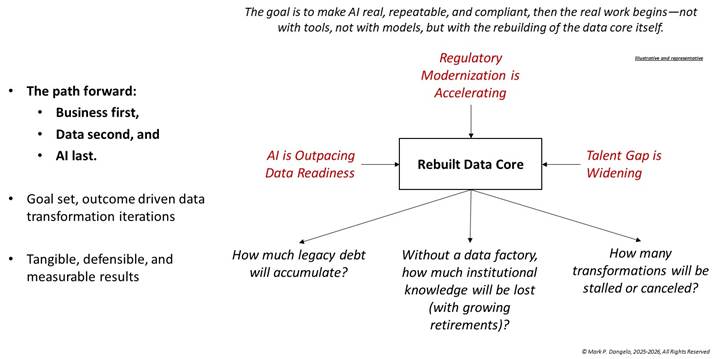
Figure 1—The Impetus for a “Rebuilt Data Core”
In theory, AI should help mortgage institutions meet these demands. In practice, many leaders are encountering the opposite effect: AI initiatives surface weaknesses in data alignment that were previously manageable through manual intervention.
What works in a pilot environment often breaks when deployed across channels, investors, or portfolios. Explanations degrade when models encounter inconsistent definitions. Compliance teams struggle to validate AI-assisted outcomes. Integration timelines stretch as data reconciliation consumes resources. The issue is not model performance. It is data architecture.
Defining the Mortgage Data Core
The mortgage data core is not a single platform, database, or vendor solution. It is the structural foundation that governs how loan data is defined, harmonized, and reused across the enterprise. An effective mortgage data core must support five non-negotiable capabilities:
• Loan-Level Semantic Consistency: Core concepts—borrower income, assets, liabilities, property characteristics, loan terms—must mean the same thing across origination, underwriting, closing, delivery, servicing, and finance.
• End-to-End Lineage: Institutions must be able to trace how data elements flowed from borrower intake through downstream decisions, transformations, and outcomes.
• Multi-Regulator Interpretability: The same data must support CFPB, FHFA, GSE, state regulator, investor, and internal risk perspectives without manual reinterpretation.
• Change Resilience: Data definitions must evolve as regulations, products, and market conditions change—without breaking downstream processes.
• Machine Interpretability: Data must be structured and governed so AI systems can reason over it without extensive human mediation.
Most mortgage organizations possess large volumes of data, but lack alignment across these dimensions. Historically, manual processes masked these deficiencies. Agentic AI removes that buffer.
The Mortgage Data Core, Revisited: Why MISMO Is Necessary—but Not Sufficient
For decades, the mortgage industry has recognized the need for common data standards. The Mortgage Industry Standards Maintenance Organization (MISMO) has played a critical role in advancing interoperability by defining shared data elements, structures, and reference models across the loan lifecycle. MISMO standards underpin modern LOS platforms, investor delivery specifications, and regulatory reporting frameworks.
Without them, today’s level of digitization would not exist. Nonetheless, as mortgage institutions attempt to scale AI and agentic AI, many are discovering an uncomfortable truth: MISMO compliance alone does not constitute a functional mortgage data core.
This is not a critique of MISMO. It is a recognition of the distinction between standardization and operationalization—a gap that becomes visible only when automation moves from transactional processing to autonomous decisioning.
Where MISMO Stops—and AI Begins
At its core, MISMO provides:
• A canonical vocabulary for mortgage data elements,
• Standardized logical and physical data models,
• XML and JSON schemas that support data exchange, and
• Reference architectures spanning origination, closing, servicing, and secondary markets.
These contributions are foundational. They allow systems to exchange loan data, enable vendor interoperability, and reduce custom point-to-point integration. For most of the industry’s history, this was sufficient. Mortgage processes were largely linear and siloed processes, and human intervention absorbed inconsistencies across systems often using APIs, warehouses, and ETL.
Agentic AI changes the threshold for what “good enough” data means. While MISMO defines what data elements are, it does not define:
• How those elements are contextualized across workflows,
• How definitions are governed and versioned as business rules change,
• How lineage is maintained when data is transformed, enriched, or derived,
• How trust, completeness, and timeliness are scored at the loan level, and
• How regulatory interpretations are operationalized dynamically.
In practice, most mortgage organizations implement MISMO differently across systems. The result is semantic drift: the same MISMO element exists, but it means slightly different things depending on source, channel, or use case. Humans can often reconcile this—AI cannot.
From MISMO Mapping to MISMO Industrialization
To support scalable AI, mortgage institutions must treat MISMO as a vocabulary layer, not the data core itself. A functional mortgage data core requires:
• MISMO-aligned canonical data products, not just MISMO-compliant fields,
• Explicit semantic governance that enforces meaning across systems,
• Automated lineage generation tied to MISMO element IDs,
• Versioned interpretations that reflect regulatory and investor overlays, and
• Machine-readable metadata that agents can reason over autonomously.
In this model, MISMO becomes the shared language—but the data foundry becomes the factory that produces trusted, reusable loan data products at scale.
Many institutions believe they have “done MISMO” because they mapped systems to MISMO schemas. In reality, they have completed only the first step. A data foundry industrializes MISMO by:
• Anchoring all loan data products to MISMO reference models,
• Capturing lineage from source systems through transformations,
• Encoding regulatory logic (HMDA, ECOA, TRID) as reusable overlays, and
• Enabling AI agents to query data with confidence in its meaning and provenance.
This is the difference between exchanging data and operating on it autonomously.
Why This Matters to Mortgage Leaders Now
As regulators increase scrutiny of AI-assisted decisioning, institutions will be asked not just whether data conforms to standards, but whether decisions can be explained in terms regulators recognize. MISMO provides that recognition layer—but only if it is embedded within an operational data core.
Mortgage institutions that elevate MISMO from a compliance artifact to an industrial foundation gain a decisive advantage:
• Faster AI deployment with lower risk,
• Stronger regulatory defensibility,
• Reduced integration friction during M&A, and
• Greater reuse of data across channels and use cases.
Those that do not will find themselves repeatedly re-mapping MISMO fields, while struggling to explain AI outcomes under pressure.
MISMO is not being replaced—it is being activated. In the era of agentic AI, the question is no longer whether institutions adopt MISMO, but whether they industrialize it through a data foundry that treats loan data as a strategic asset rather than a transactional byproduct.
For mortgage leaders navigating 2026 and beyond, this distinction will separate organizations that scale AI with confidence from those that continually reset under scrutiny.
From MISMO Alignment to Foundry Execution: Where AXTent Fits
If MISMO defines the mortgage industry’s shared language, the unresolved challenge for most institutions is turning that language into an operational system that scales across AI, compliance, and integration demands. This is where many transformation efforts stall. Data standards exist, but they are implemented unevenly. Governance frameworks are documented, but not enforced. Lineage is reconstructed after the fact. AI initiatives proceed, but only within narrow, fragile boundaries.
Bridging this gap requires more than mapping fields or adopting another platform. It requires an execution model that can operationalize MISMO at enterprise scale, while remaining adaptable to regulatory change, investor variation, and evolving AI use cases. AXTent (an advanced data design deploying domain data meshes and cross-connected data fabrics deployed across a data foundry) is designed to serve precisely this role.
Rather than replacing LOS platforms or data standards, AXTent functions as a semantic and governance execution layer that sits between source systems and downstream consumers. It anchors loan data products to MISMO reference models, while enforcing consistency, lineage, and reuse across channels, systems, and workflows. As illustrated in Figure 2, AXTent transforms MISMO from a static standard into a living, machine-interpretable foundation.
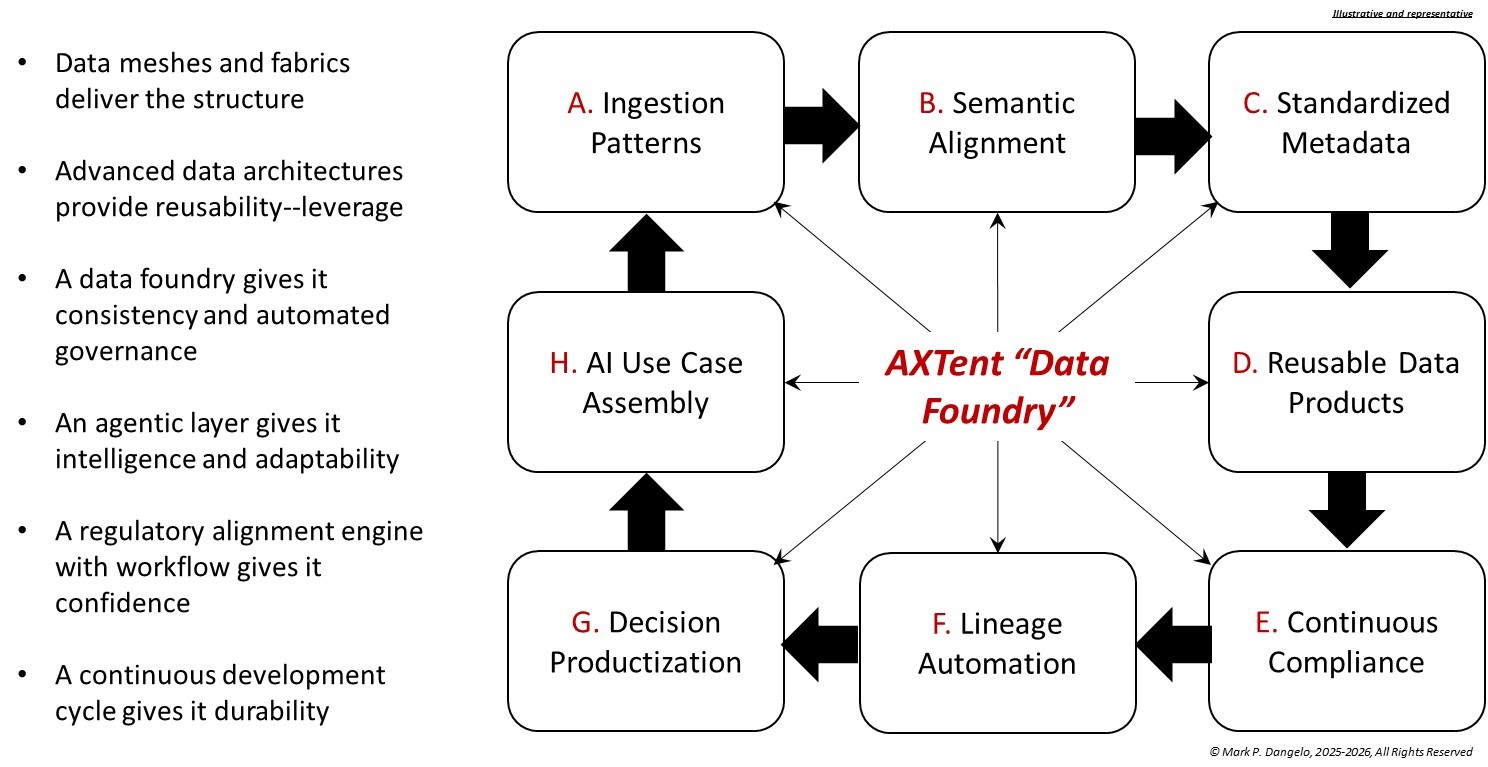
Figure 2—The AXTent Data Foundry Architecture Concept
This approach is particularly critical as institutions move toward agentic AI. Autonomous systems cannot rely on human interpretation to reconcile semantic differences or validate data trustworthiness. They require data that is consistently defined, fully traceable, and governed by design. AXTent enables this by embedding MISMO-aligned semantics, versioning, and lineage directly into the data creation process—before AI agents ever act on the information.
Importantly, this model does not assume a single implementation path. Mortgage institutions vary widely in size, channel mix, and technology footprint. AXTent supports incremental adoption, allowing organizations to industrialize high-value loan data products first—such as underwriting, compliance, or secondary market datasets—while building toward a broader data foundry over time.
In this way, MISMO provides the vocabulary, AXTent provides the execution discipline, and the data foundry emerges as the outcome: a scalable, regulator-ready foundation capable of supporting AI, agentic automation, and continuous reinvention without repeated rework.
The Data Foundry: An Industrial Model for Mortgage Data
A data foundry represents a fundamental shift in how mortgage data is produced and consumed. Instead of preparing data on a project-by-project basis, the enterprise industrializes the creation of standardized, reusable data products. In a mortgage context, these include:
• Loan Data Products: Canonical borrower, property, income, asset, liability, and credit objects.
• Compliance Data Products: TRID, ECOA, HMDA, fair lending indicators, and audit artifacts.
• Secondary Market Data Products: Investor eligibility, pricing adjustments, delivery validation datasets.
• Servicing Data Products: Payment behavior, escrow status, loss mitigation signals.
Each product is governed, lineage-enabled, versioned, and designed for machine consumption. AI systems no longer operate on raw loan files; they operate on trusted, explainable data assets. This shift mirrors industrial manufacturing: standardized components replace bespoke assembly, enabling scale, consistency, and reuse.
Conclusion: AI Is the Output. The Data Core Is the Strategy.
Mortgage banking has indeed reached an inflection point. Agentic AI will become standard practice—whether institutions are prepared or not. The determining factor will not be access to AI tools, but the strength of the data core, and its advanced AI data architecture (i.e., AXTent data foundry) beneath them.
The critical question for 2026 and beyond is not: “How do we deploy AI?” It is, “How do we rebuild the mortgage data core so AI can operate safely, explainable, and at scale?”
Institutions that address this proactively—by adopting a data foundry model—will define the next era of mortgage banking. Those that defer will find themselves reacting under regulatory, operational, and competitive pressure.
AI is inevitable. Outcomes are not. The future of mortgage banking will be decided quietly, deep within the data core.
(Views expressed in this article do not necessarily reflect policies of the Mortgage Bankers Association, nor do they connote an MBA endorsement of a specific company, product or service. MBA NewsLink welcomes submissions from member firms. Inquiries can be sent to Editor Michael Tucker or Editorial Manager Anneliese Mahoney.)