What Comes Next for AI in the Mortgage Industry

As 2026 arrives, mortgage banking and the traditional processes honed over decades sits at a crossroads of clarity. After years of contraction, margin compression, unpredictable regulatory expectations, and an ongoing technology hangover from the last decade, lenders now face a new inflection point: AI solutions have finally outgrown their pilots in their demands for cross-functionally integrated data.
As the new year arrives, and built on the bones of 2023-2025 realities, the industry will be forced to reconcile decades of data legacy debt, fragmented data supply chains, aging core systems, and inconsistent data governance specifically designed for AI oversight. The days when AI meant “intelligent OCR,” workflow efficiency rules, and lightweight analytics and dashboard prediction models are over.
How did it come to this?
The intelligent evolution will be driven not by traditional AI, but by emerging agentic AI, tightly coupled with retrieval-augmented generation (RAG), domain focused data meshes, and cross-functional data fabrics that create compartmentalized, immutable, traceable data capable of scaling across the enterprise. Gone are the days when a single advancement can address the complexity and levels across data and operational requirements.
Figure 1 illustrates the 2023-2025 structural faults, which contributed to the fragmentation and misapplication of AI, and the root cause that needs to be proactively addressed across 2026 production-scalable solutions.
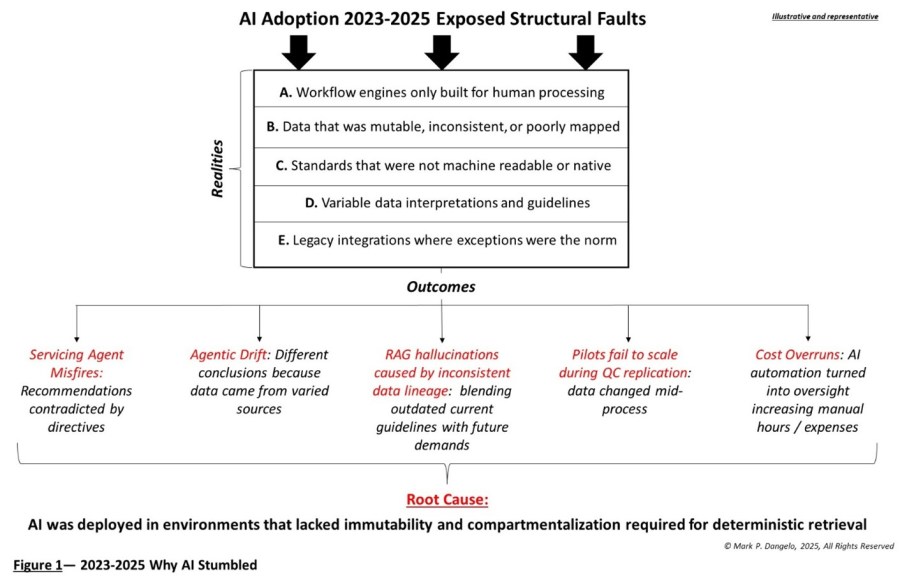
For an industry built on precision, compliance, and risk containment, this shift represents both challenges and opportunities. The winners will be the institutions that anchor their AI ambitions in data engineering discipline, governance maturity, and a modular data core designed for explainability and regulatory scrutiny.
The Industry’s Reality Check: AI Isn’t the Bottleneck—Your Data Is
After years of experimentation—model pilots, workflow modernization, point-solution “AI enhancers”—the industry now understands two things: first, AI will reshape origination, servicing, secondary markets, and risk oversight; second, none of the promised value will scale without a fundamentally different relationship with data.
Most lenders are not short of AI pilots. What they lack is the ability to scale them without:
• Triggering downstream exceptions,
• Compromising regulatory reporting,
• Exceeding cost-to-value thresholds,
• Delivering tightly coupled, auditable data tracing,
• Mandating “state captures” over time
• Introducing new layers of data reconciliation, or
• Requiring humans to “fix” or validate model outcomes.
This is the paradox: AI boosts efficiency only until it collides with legacy data structures. At that point, everything slows. Quality deteriorates. Compliance burdens increase. And the original business case evaporates.
The fundamental issue is data fragmentation:
• Data sits in departmental silos—originations, risk, QC, fraud, servicing, investor reporting.
• Unstructured files (bank statements, income docs, disclosures) remain opaque.
• Lineage is incomplete or broken during every extraction, transformation, and vendor touch.
• Legacy integration patterns create unintended mutations or partial records.
• Model outputs are not traceable to original data sources.
The mortgage industry “knows” its data. It just can’t trust it at scale. The next wave of AI will not be about bigger models—it will be about trustworthy, compartmentalized data ecosystems designed for automation and governed by highly granular, immutable controls.
In Figure 2, we showcase the number of interconnected drivers that must be aligned for not just initial AI solution adoption, but continuous improvement and adaptation as the technology undergoes rapid iterations against exploding data volumes, variety, and variability.

Structural Reality: The Data Core Is the Consistent Constraint
For years, data mesh and data fabric were discussed conceptually, but rarely executed in mortgage banking. Today, their resurgence reflects an urgency: lenders need agility without ripping out core systems especially with the growing benefits of AI—coupled with an inability to scale due to data fragmentation.
A data mesh decentralizes data ownership. Instead of central IT cleaning, cataloging, and provisioning all data, each business domain becomes a producer of certified, reusable data products.
In a mortgage context, this means:
• The Originations Mesh Node produces verified borrower data, digital asset packages, income calculations, disclosure history, and structured documentation metadata.
• The Risk & QC Node curates credit risk features, fraud flags, audit trails, compensating factors, and model outputs with deterministic lineage.
• The Servicing Node provides account history, loss mitigation status, escrow trajectories, and payment anomalies.
• The Secondary Markets Node exposes loan packages, pricing adjustments, repurchase risk indicators, and model-verified data tapes.
Each domain produces immutable, version-controlled data products that AI agents, processes, and humans can trust without revalidation. This reduces redundant data handling, reconciliations, and cross-functional firefighting.
A data fabric creates the connective tissue—governance, metadata management, security, and orchestration—between these nodes. A data fabric is an intelligent integration layer needed for data-driven AI ingestions.
The fabric:
• Standardizes lineage,
• Enforces access control,
• Maintains schema and taxonomy consistency,
• Synchronizes updates across vendors and systems,
• Provides semantic understanding of data, and
• Enables real-time decisioning through API and event-driven patterns.
In short, data mesh = who owns the data. The data fabric = how the data moves and remains trustworthy. Together, they create a foundation aligned with AI, regulatory expectations, and the realities of future mortgage operations.
Regardless of the benefits of data, many leaders struggle with how to start. Where do we begin and is there an illustrative roadmap of what this this require—aka what are the implications of the strategy? Figure 3 provides this representation ingesting the 2023-2025 structural challenges to arrive at realistic call-to-action phases.
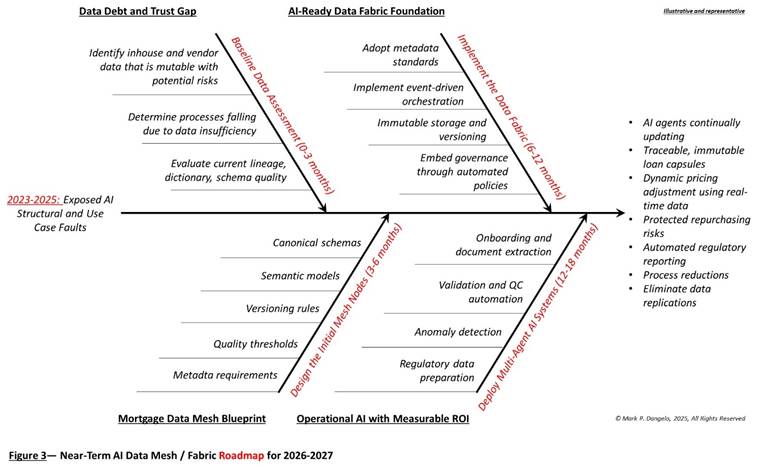
One final key consideration that leaders must recognize and mitigate—the emergence of Agentic AI will never scale across fragmented data silos or ETL / warehouses. The promises of this next iteration of AI compartmentalized building blocks that can adapt and rationalize is built on common data across the required interoperability and architectures. If you think there were challenges with GenAI or AI RAG, then Agentic AI and Agentic AI with RAG will represent “Future Shock.”
The Strategic Imperative: It’s About the Data Architecture
As organizations ask what comes next in AI, the answer is increasingly clear: AI without a modern, compartmentalized, traceable, and immutable data core will stall. The next era of transformation will be built not on isolated models, but on data meshes, data fabrics, and agentic AI architectures that create reusable, trustable, and compliant data flows across the entire mortgage lifecycle.
The mortgage industry has spent three decades digitizing its processes, yet it still operates with the assumptions of a paper-first world: batches, checkpoints, handoffs, sampling, and workflows built around human interpretation. AI entered this environment with great expectations, but reality quickly demonstrated a harsh truth—models do not transform industries unless the underlying data is trustworthy, traceable, and built for real-time retrieval.
The next phase of mortgage modernization is not a technology sprint; it is a data engineering journey supported by AI. Agentic systems as envisioned will rewrite the playbook, but only for lenders who first stabilize the data core. The ones who move early—who commit to immutability, mesh-based architectures, explainable AI, and RAG-driven workflows—will define the industry’s next decade.
The lenders and servicers who invest now will operate with lower costs, lower risks, higher scalability, and far greater consumer trust. Those who delay will spend the next decade repairing systems that were never designed for AI-native operations—or more than likely, becoming acquisition targets for those who embraced their data.
The path is clear. The question is who will take it and use it to create the architectural foundations needed not just for current AI solutions—but what will become increasingly commonplace in 2026.
(Views expressed in this article do not necessarily reflect policies of the Mortgage Bankers Association, nor do they connote an MBA endorsement of a specific company, product or service. MBA NewsLink welcomes submissions from member firms. Inquiries can be sent to Editor Michael Tucker or Editorial Manager Anneliese Mahoney.)