The Death of Data: Why is BFSI’s Data Increasingly “Obsolete?”

Mark Dangelo currently serves as an independent innovation practitioner and advisor to private equity and VC funded firms. He has led diverse restructurings, MAD and transformations in more than 20 countries advising hundreds of firms ranging from Fortune 50 to startups. He is also Associate Director for Client Engagement with xLabs, adjunct professor with Case Western Reserve University, and author of five books on M&A and transformative innovation.
The mantra for data inclusion and storage has centered around “data is an asset” be it FinTech, RegTech, or traditional banking and lending solutions. Yet, when does the asset become a liability, or worse, how can we tell if it is making the enterprise execute weak strategies, decisions, and even reskilling options?
As digital data explodes year after year, the drumbeat of data ingestion accelerates forcing Banking, financial services and insurance (BFSI) organizations to identify, integrate, and store vast amounts of structured, unstructured, and synthetic data all in the hope that it can be tapped for decision making and revenue growth. Yet, while the focus and budgets underpinned by sophisticated cloud capabilities drives the mantra of “more, more, more,” should that be a primary business and IT goal? Is the solution to deploy AI or deep learning against these vast, disjointed data repositories in a hope these artificial wonders of the world can find the hidden meaning within?
Beneath the “magic” that is (generative) AI, the reality is that these large language models (LLM) applied to public data or ring-fenced private industry databases are complex, ensembled solutions (i.e., layered technology). These data-driven capabilities for BFSI enterprises dealing with non-traditional competitors struggle to ingest data against their legacy, core banking and lending systems. The data ingestion methods and techniques continue to revolve around a system-ideation approach to creating data—not identifying data-as-a-product (DaaP) utilized by virtual (lending) and Neobank products and services.
For clarity, DaaP is different from software-as-a-service (SaaS) in the design and desired outcomes. DaaP drives revenue from insights and correlations spread across traditional system boundaries. DaaP is designed for multi-faceted information sources and uses which leverages structured, unstructured, and semi-structured data and metadata using a federated system of integration. DaaP are building blocks that promote data reuse (and cost savings), while delivering quality information within a changing BFSI ecosystem and consumer behaviors. DaaP is analogous to the Lego’s that come in countless shapes, sizes, and colors—depending how you stack them you can get the varied results from the same Lego.
DaaP is not a panacea, but it does represent the next approach to identifying, designing, and implementing BFSI systems. However, before we rush off to build our reusable DaaP building blocks, an overview of the ecosystem characteristics is the first step of adoption.
What is the Data Ecosystem
A common misconception is that DaaP is only about analytics. Early-stage ideas around this rapidly evolving ideation formed because of business analytic platforms and executive dashboard initiatives. With the evolution of FinTech and RegTech coupled with huge advances in cloud computing, the underlying data management that was secondary to operational processes has evolved into active data governance and DataOps. Now with the focus on intelligent RPA, ML, and AI, DaaP continues to evolve in importance and in capabilities within and across BFSI enterprises.
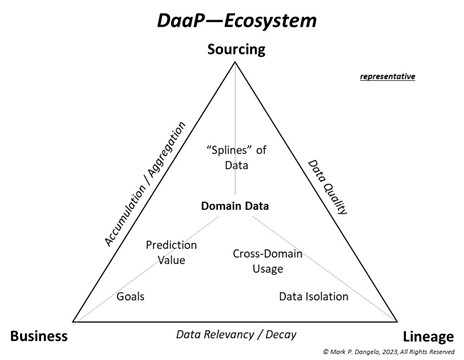
In 2019, data virtualization underwent a step-function shift within BFSI with the introduction of data meshes and fabrics designed to define and crosslink functional data domains. Additionally, using “splines and fins” architecture borrowed from fault tolerant cloud data centers, data ecosystems (see figure to left) exploded with untapped value and future promise. These capabilities, along with shifts of consumer behaviors spurred by a global pandemic, kickstarted DaaP efforts broke their analytic origins. The outcome was that industry demands for robust data quality hemmed in the domain data. Demands from investors and consumers focused on transparency of information, understanding the decision logic, and most importantly, the sourcing of the original documents and artifacts that were enveloped in manual or automated decision making.
What these shifts and transformations resulted in was a tight focus on the value, use, manipulation, and lineage of data not just within a silo of a CRM, LOS, AVM, or even servicing, but a cross linkage of a common data product that could be constructed and deconstructed to deliver decisions, provide auditability, and to address the growing complexity and expense of regulatory compliance. For DaaP, the ecosystem becomes the starting point—not the technology. Yet this is just the first step of three on the BFSI journey to incorporating DaaP across the multitude of legacy systems already deployed. For illustrative references, JPMorgan in mid-2021 and Fifth Third in late 2022 released their early-stage experiences and outcomes using data meshes with implicit DaaP criteria. This is not an academic exercise or theoretical undertaking.
However, if we accept that our data must be uniquely designed for reuse delivered using a “data isolation module” or DIM building block, then why can’t we go directly to implementation? As part of an active data governance and lineage technology stack, the context of its usage is as important as its content we covet.
What Determines DaaP Contextualization?
Data context seems like an odd concept—especially for BFSI leaders dealing with competition, declining margins, revenue voids, and market disruptions. Yet, against growing security and privacy requirements coupled with growing and fragmented data regulations on usage and ethical sourcing, context of data within DaaP is a critical element of consideration when determining how the data should be used, who can access it, how long is it valid, and where did it come from (e.g., duplication anyone?). Is the data we use for decision making obsolete before we feed it into our AI solutions, let alone AI feeding other downstream, cascading AI capabilities all making inferences and recommending actions from a set of data perhaps with no context?
It should be noted, that over 60% of data within the BFSI storage arrays is never used once it is captured. When you consider that data volumes are doubling every 2.5 years, the ability to tap into “dark” data is much like hunting for the light switch without any idea where it might be. Indeed, the promise of AI is to find these “hidden” gems, opportunities, correlations, and predictions buried deep within the siloed data spanning hundreds of BFSI systems. Yet, if the data is replicated, manipulated, and enhanced with synthetic data, then what is the “real” data being acted upon? Is it accurate? Can it be trusted? Will the decisions be valuable—or a liability?
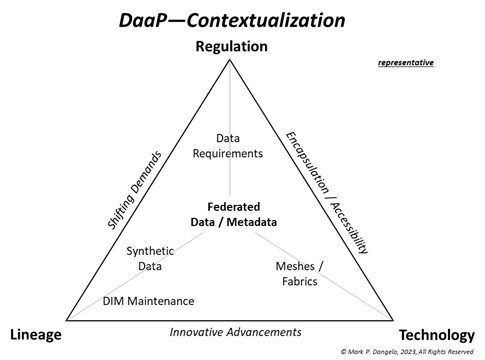
The diagram above shows the boundaries of requirements where context must be considered—shifting demands, encapsulation and accessibility, and innovative advancements. These triple constraint boundaries encase data approaches and solutions that balance the lineage, technology and regulation of data usage and storage. At the heart of the DaaP contextualization resides the federated data and metadata integrating varied systems of record (SOR) within BFSI, their partners, and outsourcers.
With the understanding of the DaaP ecosystem and contextualization, now leaders can begin to undertake the familiar DevOps and deployment methods using COTS system development kits (SDK’s) and process rules driven solutions. Yet is it a linear process? Is the operation and maintenance of DaaP a lift-and-shift for integration into traditional customer and lending solutions?
How Can DaaP Implementation Leverage the Existing?
DaaP is an abstract idea implemented using currently available technologies and solutions—data meshes, AWS “Glue”, data sovereignty, data governance and controls, and even AI encased within emerging chipsets.
Yet for all the innovative advancements in compartmentalized technologies and data management, DaaP is adaptative since it is not defined nor constrained using traditional system ideations found in FinTech, RegTech, or core banking and lending solutions. By decoupling the data from the systems, and using architectural design abstractions, the achievement of reusable building blocks of immutable, transparent, and resilient data can be delivered to BFSI firms seeking greater IT returns (see illustration below).
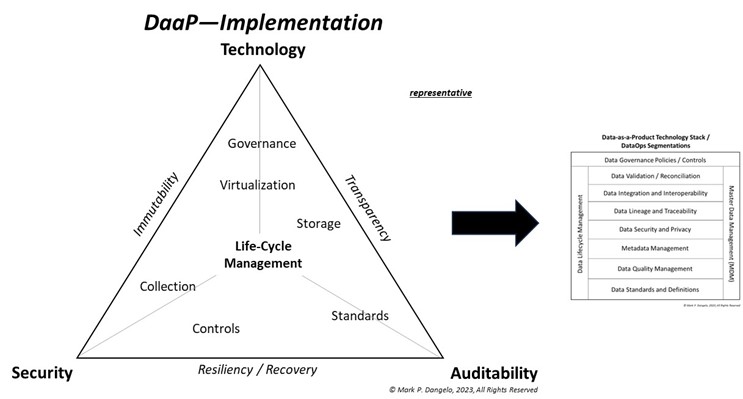
DaaP once defined, undergoes a life-cycle management process and maintenance familiar to Devops teams but concentrated on data—which is DataOps as shown in supporting DaaP technology stack on the right side of the above figure.
One other factor that is always asked, especially within highly regulated industries such as BFSI, is where do standards (e.g., MISMO) play within the DaaP ideation? They provide the robustness needed for auditability and they are an element of the overall DaaP module definitions. In fact, without a solid foundation of standards and data controls, DaaP is not possible except on a case-by-case basis. Standards represent an evolutionary stage to reach the principle of DaaP reusability.
In summary, SaaS was (generally) designed for software usage via cloud solutions to eliminate the need for on premise installations achieving rapid system provisioning at reduced costs. DaaP is designed around leveraging data for accurate, advanced data-driven insights and decision-making which SaaS software could utilize. SaaS is a system ideation, process automation implementation and DaaP represents data insights, behaviors and trends deployed with reusable building blocks. Stated differently, SaaS is traditionally about the process—DaaP is about quality, reusable data for SaaS (across the process silos).
SaaS is not the wrong approach—it has provided the foundation, like many technological events, for a “next” iteration of solutions. DaaP represents this next evolution of ecosystems, contextualization, and implementation segmentations, driven by market shifts, consumer behaviors, and technical advancements (e.g., AI).
DaaP is also not a theory or only for those firms with huge IT budgets. Across industries, and even within those firms delivering tax and audit services, DaaP is what they are actively designing and delivering as part of a growing array of AI capabilities. To efficiently leverage intelligent RPA, ML, and AI, DaaP is becoming the starting point for reducing errors, improving the customer experience, and creating consistency for the explosion of data elements spinning dark within cloud and on-premises storage. DaaP also represents a means to “level the playing field” between small community banks and credit unions—as these major BFSI enterprises continually add zeros to their asset base.
Indeed, what we are all discovering with the banking failures this year, is that systems are wonderful, but what data are you watching? Is what we are coveting as assets critical today and tomorrow—or have they reached their expiration date? Data does become obsolete, a liability, and a cost-burden. Could DaaP ideation and implementation be a solution to compete and grow? The answer can be seen in a growing chorus of adoption, expansion, and investment in this Fourth Industrial Revolution innovation.
(Views expressed in this article do not necessarily reflect policy of the Mortgage Bankers Association, nor do they connote an MBA endorsement of a specific company, product or service. MBA NewsLink welcomes your submissions. Inquiries can be sent to NewsLink Editor Michael Tucker at mtucker@mba.org or Editorial Manager Anneliese Mahoney at amahoney@mba.org.)